Unlocking the secrets of life through data science

When data scientist Anirudh Prabhu arrived at the Earth and Planets Laboratory in 2021, he discovered he’d be sharing a snack-filled office with postdoc Michael L. Wong, an astrobiologist and planetary scientist who was eager to dig into data-science. While Prabhu is committed to applying data analysis and machine learning to scientific inquiry, Wong is studying some of humanity’s biggest questions like: “How do we find life on other planets?”, and “No, seriously, what even is life?”

Mike and Anirudh pose for a photo together at the 2022 Carnegie AGU alumni reception.
That second one turns out to be pretty hard to answer. But this unlikely pair discovered that combining their expertise allowed them to take it on from an informatics perspective—developing a new framework for understanding life in the process. Their paper, recently published in the Journal of the Royal Society Interface, explores how two data science concepts—the “information life cycle” and the “data–information–knowledge ecosystem” can be used to describe life as we know it (and life as we don’t).
The big question
Biologists traditionally use a list of complex physiological functions to define life: the ability to maintain stability in the face of changing conditions, organization, metabolism, growth, adaptation, response to stimuli, and reproduction. In 1994, a NASA committee tried to pin down the definition to suit the search for life on other planets. They homed in on a single sentence, proposed by the legendary Carl Sagan: “a self-sustaining chemical system capable of Darwinian evolution.” But while it’s concise, this definition doesn’t necessarily paint the whole picture.
Meanwhile, humans seem to have an intrinsic understanding of what life is here on Earth. You’re alive; the fiddle leaf fig you bought during COVID is alive (barely); the bacteria in the soil are alive. But a chunk of granite? No. Definitely not.
Yet, even though the rocks and minerals that make up our planet are definitely not alive, they have played an important role in the history of life on Earth.
For example, in our planet’s early years, it’s likely that clay minerals containing reactive iron and nickel enabled the chemical reactions that produced the first organic molecules. There’s even some thought that minerals in the early oceans may have moderated complex reaction chains that laid the foundation for molecular replication—which is necessary for the rise of life.
“As an astrobiologist, one of the deepest questions that I wrestle with is, ‘What is life and what distinguishes life from non-life?” Wong explained, “When we want to search for signs of life on another planet or try to understand the origin of life out of abiotic chemistry, we need to know what actually distinguishes a living system from a non-living system.”
It was during a casual conversation about the information life cycle with Prabhu in their shared office that a lightbulb turned on for Wong. He went home and created a graphical representation of the information life cycle mapped to biological processes—discovering a surprisingly good fit between the two visual representations.
Cells as Earth’s first data scientists
According to Prabhu, any data scientist worth their salt goes through five major steps of the information life cycle when dealing with data: acquisition, curation, preservation, stewardship, and management. After the initial series is completed, the managed data becomes the next starting point and the cycle begins again, perpetuating and refining itself.
“These are the high-level steps we should follow every time we create a new data object or a data resource,” explains Prabhu. “If some of these steps are skipped along the way, it becomes harder and harder when someone else has to use the information.”
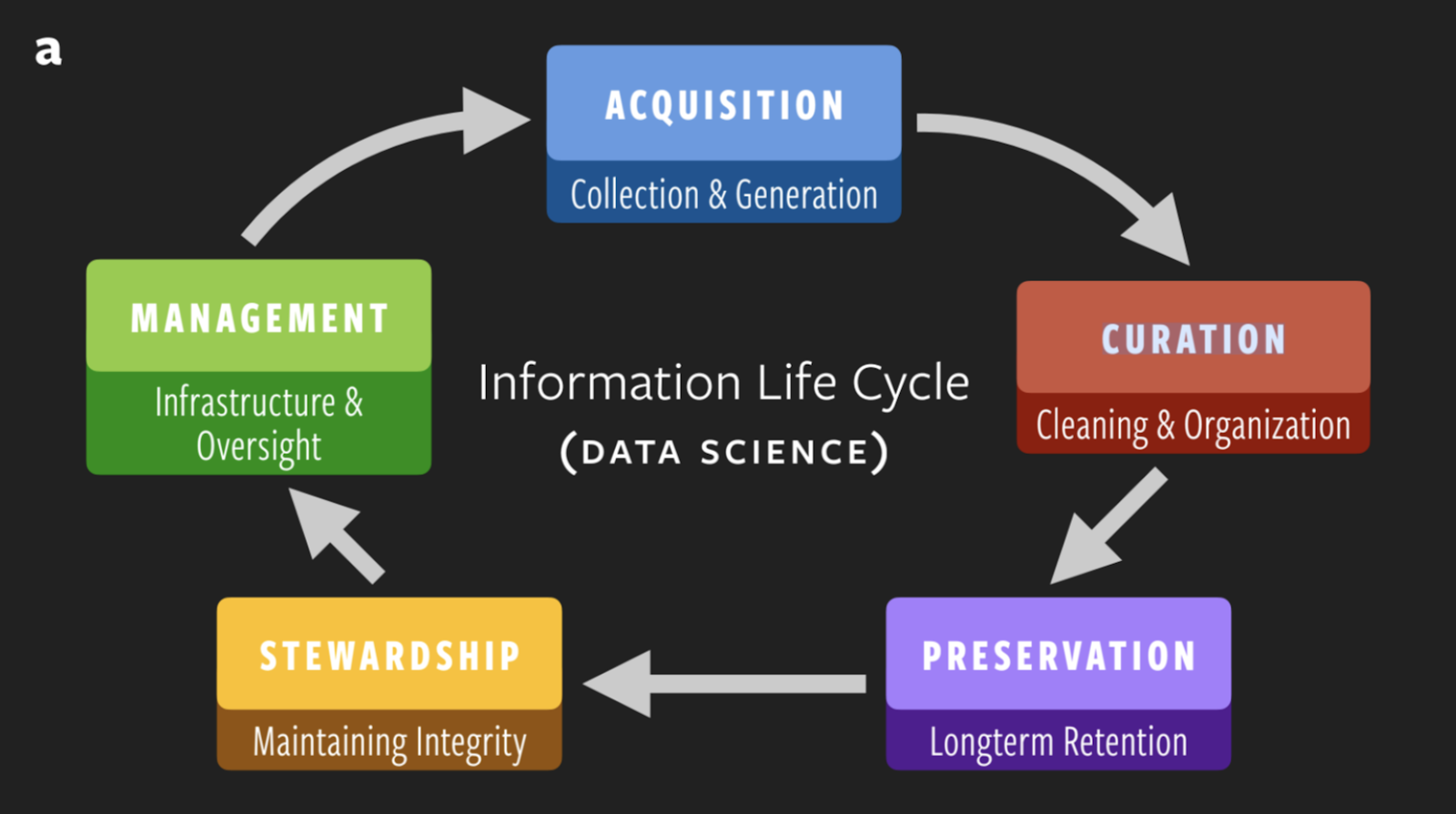
Making the case that information processing is a central aspect of life, the team compared the traditional information life cycle to biological systems. As it turns out, even the most basic organisms make excellent data scientists!
The acquisition stage is the generation of novel genetic sequences—driven primarily by mutations, along with recombination and horizontal gene transfer. The curation stage is performed by natural selection, which prunes a wide range of possible information combinations down to a smaller number of viable ones. The preservation stage is achieved through replication and reproduction, allowing those viable genomic combinations to persist through time. The stewardship stage is performed by error-correcting mechanisms, like the enzymes that proofread the DNA replication process. The management stage involves a host of mechanisms that control gene expression, such as epigenetics.
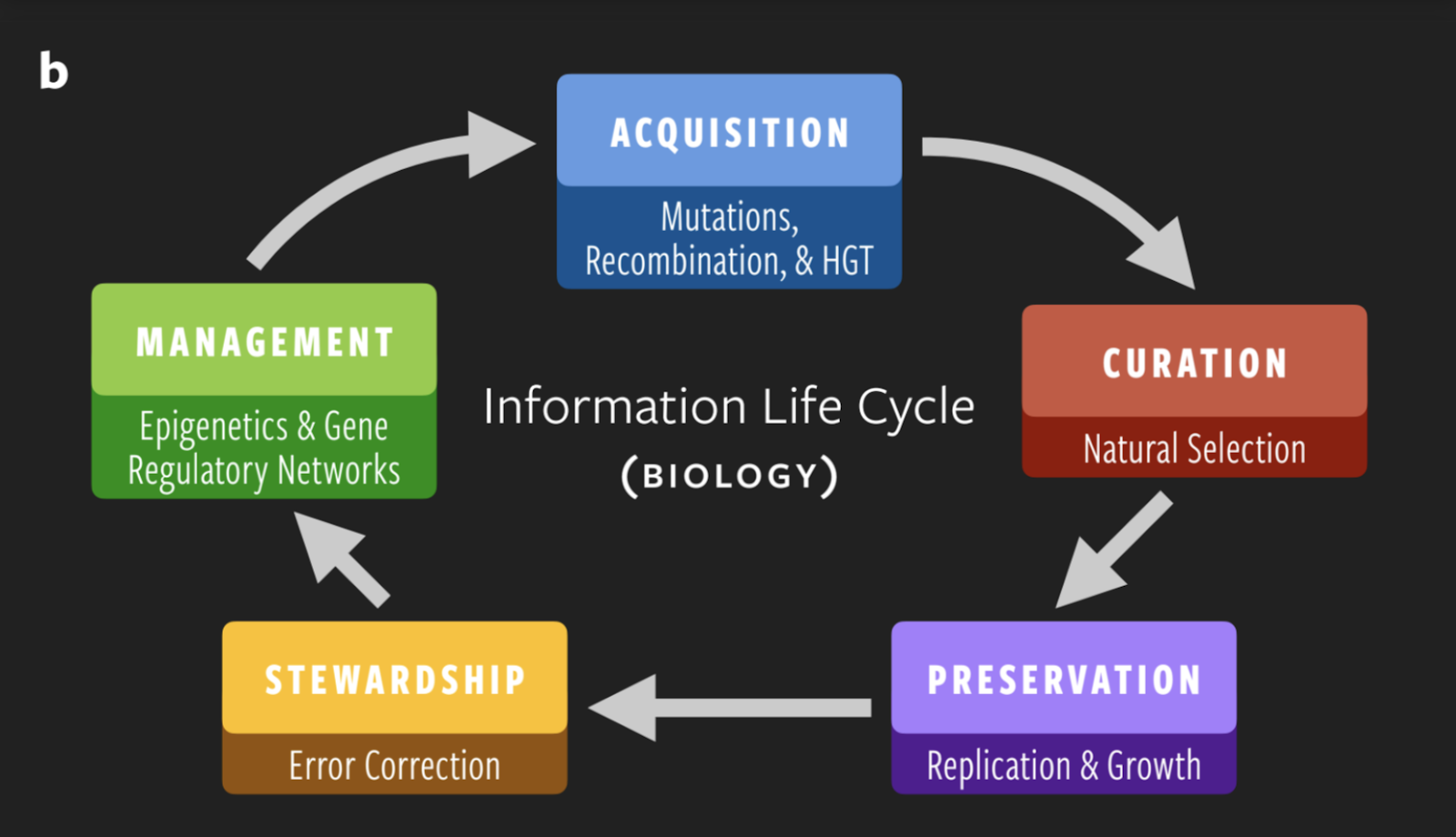
“To me, it was really fascinating that this information life cycle from data science, actually describes information in life itself,” says Wong.
The individual as information
Another key to understanding life from an informatics perspective is how organization and application create functional knowledge. Traditionally, data scientists use a pyramid to show how information is built from a foundation of raw data, leading to knowledge and, eventually, wisdom.
Prabhu thinks that approach is too one-directional, so he uses what he calls a “data ecosystem.”
“The way data is transformed into knowledge and back again is more like a fluid ecosystem, in which each component interacts with the other, and there are plenty of feedback mechanisms,” says Prabhu.
In the data ecosystem, raw data is collected and is organized, and presented as information before it can be integrated into knowledge.
Imagine planning to bake a cake. In this case, your cabinet full of ingredients is the data. You need that raw data to be organized in the form of a recipe and integrated by the process of baking. But the ecosystem is adjustable. When you cut into a slice of cake, you may discover that you want it to be fluffier, so you talk to your friend, who suggests that you adjust the recipe, and so you add another ingredient to your cabinet for the next bake.
After a while, you’ve tested your recipes on all your buddies. Some cakes are great, but the feedback you get means that some cakes don’t make it into your recipe book. You’ve built up your knowledge of which cake will win a crowd over, and it’s changing what information you decide to keep around. So now, when you’re asked to bake a birthday cake, you know which recipe to go to even though you’ve never baked a cake for that specific crowd before. That knowledge is integrated into the system.
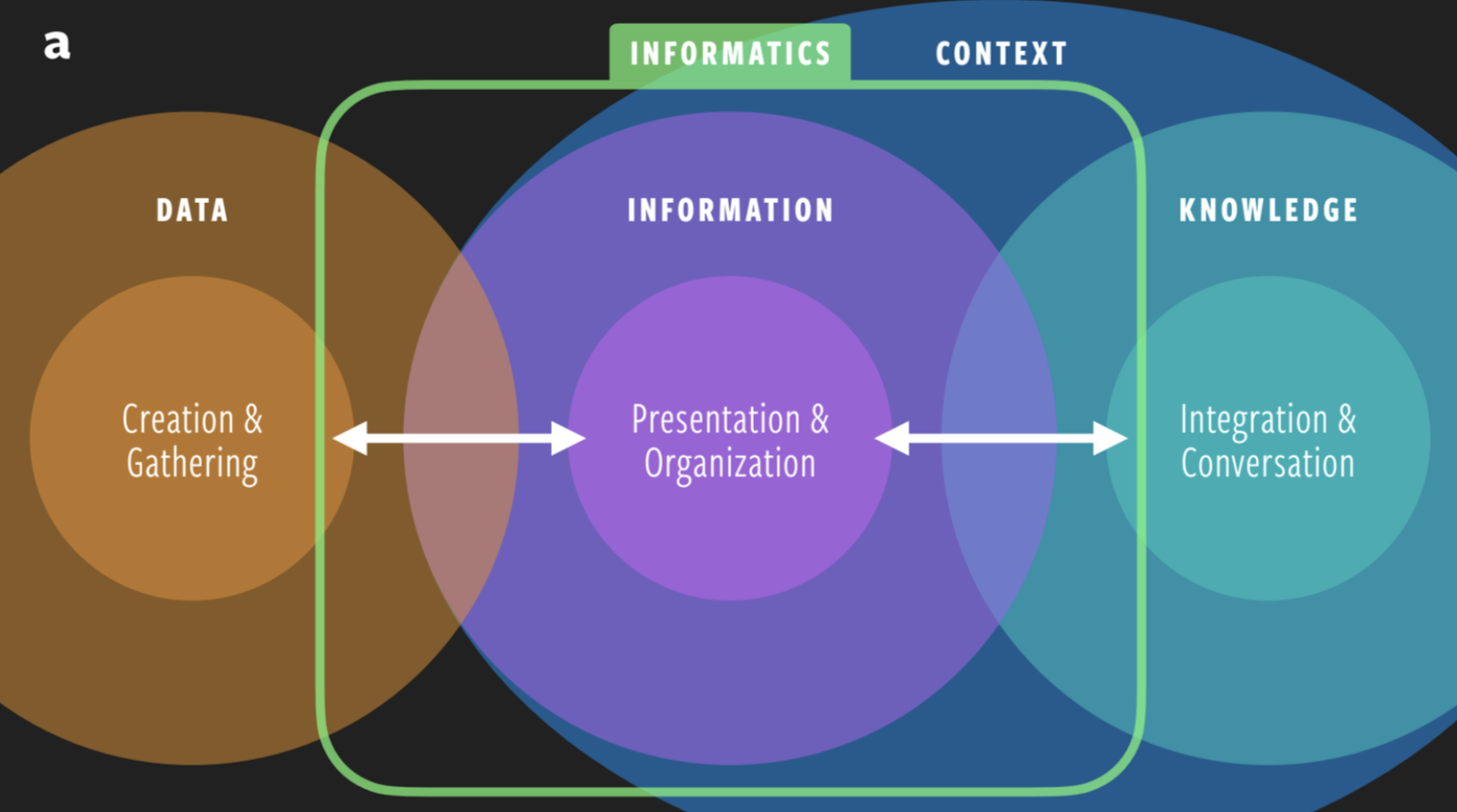
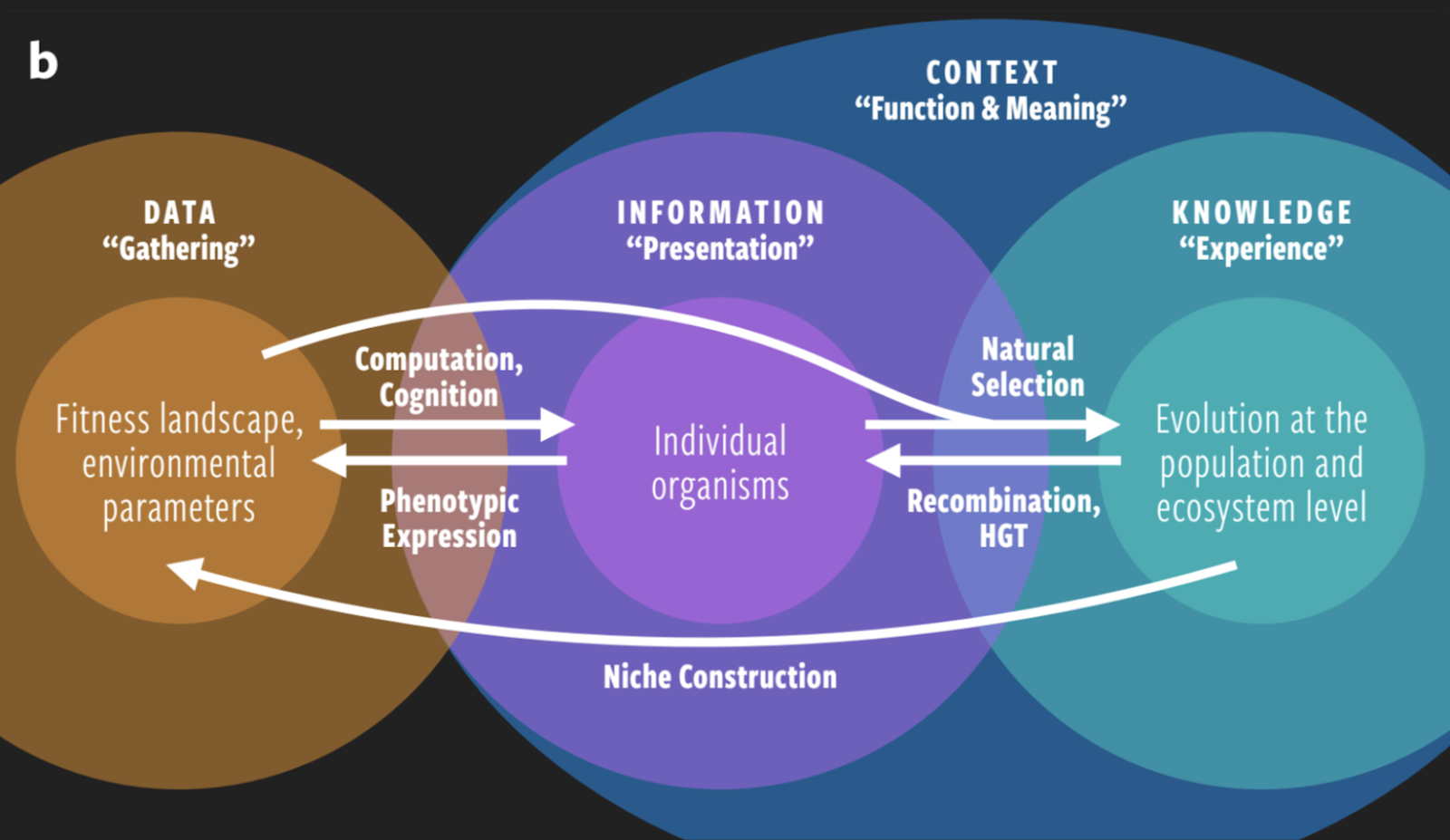
Wong and Prabhu apply this bi-directional flow of information to better understand how information shapes biological systems, from the raw data held in the environment to the library of knowledge contained within an entire ecosystem.
Wong explains, “A living system’s ‘data’ is the parameters that define its fitness for an environment, such as temperature, pressure, or pH.”
Building from there, the DNA housed in the cells of individual organisms comprises the ‘information,’ which is presented through their physical traits and behaviors. Over time, this is transformed into population-level ‘knowledge’ through the process of natural selection.
Throughout the long arc of Darwinian evolution and natural selection, biological systems go through the information life cycle to process information and gain intrinsic knowledge about their environment that helps them survive. According to Wong and Prabhu, this organizing of data in a way that increases a system’s ability to persist leads to a measurable increase in the system’s “functional information.” The authors argue that through this process, functional information within the system will naturally increase over time.
But much like adjusting a cake recipe, they also suggest that knowledge can flow back through the ecosystem as populations add new raw data to their environment.
Wong says, “Look at any symbiotic relationship, like lichens, which are the coevolution between bacteria and fungi, and you’ll see pretty clearly that there's also a back and forth going on where an individual or a population of evolving individuals creates new data that the rest of the biosphere can synthesize into knowledge.”
Defining life with informatics
With this informatics approach in mind, the line between living and non-living systems suddenly becomes a little bit clearer. Non-living systems simply don’t complete the data life cycle. Wong and Prabhu argue that, as a result, non-living systems should contain significantly less functional information.
Take minerals, for example.
Mineralogists often describe minerals as time capsules, because of how much information they acquire over the course of their existence. Their chemical composition can hold details about things like where and when they formed, if they’ve reacted with water, if they’ve melted inside of a planet, or if they’ve slowly cooled in the vacuum of space.
Minerals also experience a form of curation as external forces apply selective pressures on their formative processes, influencing which minerals form—for example, the ones that are the most thermodynamically stable stick around. One might even be able to argue that some minerals undergo preservation through their natural resistance to change.
But, that’s as far as it gets. The life cycle doesn’t continue, and the information is never synthesized into knowledge.
So, while minerals may contain deep, complex information about themselves and their environments, they don’t do anything with them. Once again, they are definitely not alive.
Wong explains, “There is no sense in which the information that is contained in minerals promotes stewardship, management, or the further acquisition of new information. So there is no complete information lifecycle.”
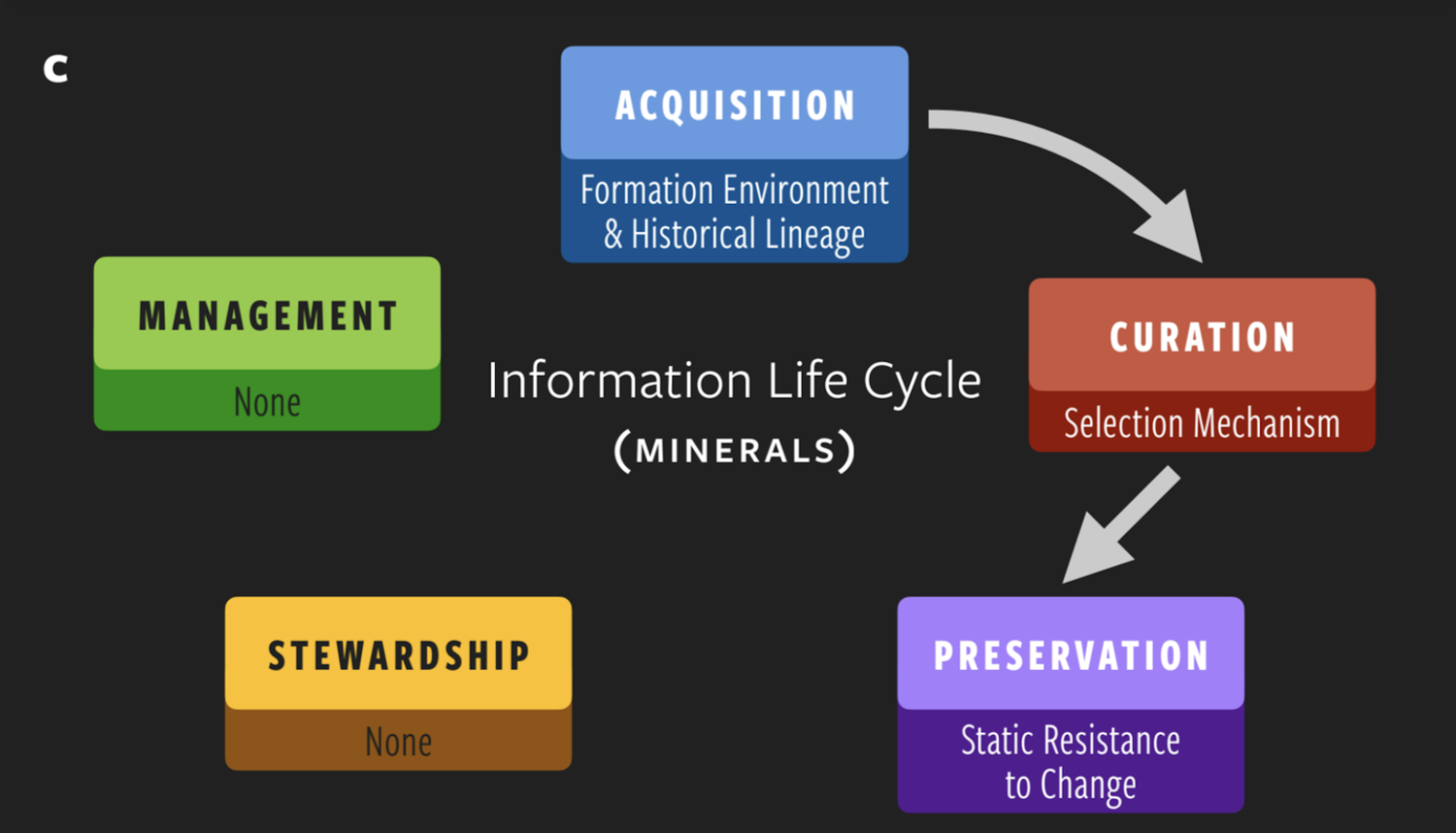
He continues, “In this particular abiotic system—and we would argue in all abiotic systems—that is a distinguishing feature between life and non-life.”
This new framework also has implications for identifying life on other worlds. Scientists might be able to use this informatics approach to identify new versions of life that don’t follow Earth-bound rules.
Wong explains, “If we went to another planet and observed some kind of complex chemical system that went through all of these information stages; then we might be able to identify it as a form of life even if it doesn't use DNA, RNA, or the same amino acids as us.”
Everything, everywhere, all at once

An abstract illustration depicting the complex relationship between data science and life. Image developed in the Midjourney AI.
The line between life and its environment is blurry. No natural system works in a vacuum—information flows between abiotic and biotic systems all the time. The authors believe that a better understanding of how data is transformed into functional information could help tie the loose ends together and tell a bigger story.
As science begins to incorporate larger data sets and our understanding of informatics increases, Wong and Prabhu suggest that we may one day be able to use this approach to form a unified and predictive theory of life that steps away from purely physics-based descriptions of our universe and relies, instead, on a comprehensive information-based understanding of the data that comprises the world around us.
For now, they are going to continue to work within the data-information-knowledge ecosystem that underpins scientific research to better support their hypothesis that non-living systems don’t complete the information life cycle.
“This paper is all about viewing biological systems through an informatics lens. Part two of this effort is to really study abiotic systems in detail to be able to prove our hypothesis,” explains Prabhu. “Definitive quantifiable proof would be excellent.”
Takeaways
- Informatics is fundamental to what life is; the way life assimilates data and uses it to enhance its own persistence could be a defining distinction between abiotic and biotic systems.
- The act of transforming data into a state that increases a system’s survivability generates functional information.
- Biology represents a subset of all known complex systems, but the information life cycle and hence the degree of functional information within them is greater compared to non-biological systems.
- Minerals are an example of non-biological systems that contain information, but the information life cycle is stunted compared to biological systems.
- Information flows between biotic and abiotic systems, blurring the distinction between life and its environment, and understanding how data is acquired and processed into functional information is instrumental in developing a theory of life.
Cells as the first data scientists
The concepts that we generally associate with the field of data science are strikingly descriptive of the way that life, in general, processes information about its environment. The ‘information life cycle’, which enumerates the stages of information treatment in data science endeavours, also captures the steps of data collection and handling in biological systems. Similarly, the ‘data–information–knowledge ecosystem’, developed to illuminate the role of informatics in translating raw data into knowledge, can be a framework for understanding how information is constantly being transferred between life and the environment. By placing the principles of data science in a broader biological context, we see the activities of data scientists as the latest development in life's ongoing journey to better understand and predict its environment. Finally, we propose that informatics frameworks can be used to understand the similarities and differences between abiotic complex evolving systems and life.
Published in the Journal of the Royal Society Interface
Read the paperRecent News


